The Piwigo.com blog
Welcome on Piwigo’s blog ! Keep in touch with Piwigo, the online image gallery software.
Latest posts

Get a sneak preview of Piwigo 14
Piwigo version 14 will be released soon and needs beta testers. The biggest news in this version is a complete overhaul of the gallery search engine. You can preview this feature and help us to test it!

New pricing for Piwigo.com: what does it change for you?
The new pricing grid for piwigo.com is now live. What does it change for existing customers? Everything is explained in this blog post.
Continue Reading New pricing for Piwigo.com: what does it change for you?

What’s new in Piwigo 13?
All customers have now switched to Piwigo 13, the latest version of Piwigo! Let’s review what’s new in this version, which focuses on user experience.

Discover Piwigo 13 in a video, and send your feedback!
Piwigo 13 is out in beta: discover all the new features in video, and give us your opinion!
Continue Reading Discover Piwigo 13 in a video, and send your feedback!

Expiry Date : a new plugin to manage expiration dates on photos
How to manage the expiration date of image usage rights and photo consents on your photo library? With the Expiry Date plugin for Piwigo, it’s easy. Today, let’s discover this new plugin designed in collaboration with one of our Enterprise customers.
Continue Reading Expiry Date : a new plugin to manage expiration dates on photos

8 examples of customized Piwigo galleries
Piwigo allows you to create a photo gallery customized to your colors. Discover 8 examples of photo libraries customized according to the brand guidelines of our customers!

Sharing and comments: how to collaborate easily with Piwigo?
Today, we focus on the collaborative features in Piwigo and especially, all the sharing features.
Continue Reading Sharing and comments: how to collaborate easily with Piwigo?

How to organize team work with Piwigo?
How does user management work in Piwigo? Who is allowed to do what? Let’s focus on user statuses in Piwigo.

Piwigo 12 is coming and needs some beta testers!
Piwigo version 12 will be released this summer and needs beta testers. Discover its new features!
Continue Reading Piwigo 12 is coming and needs some beta testers!
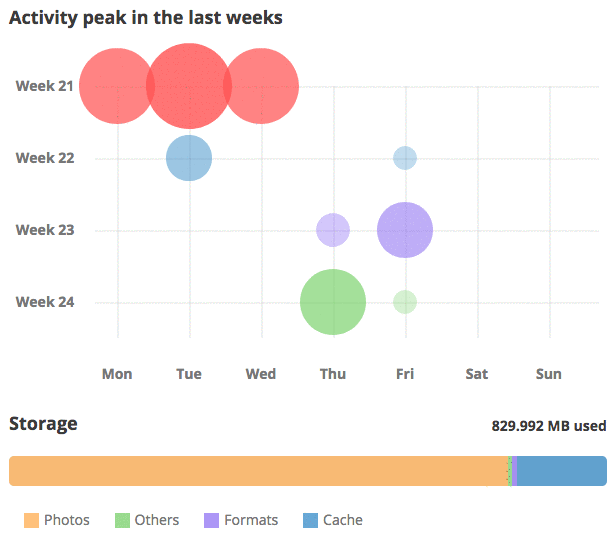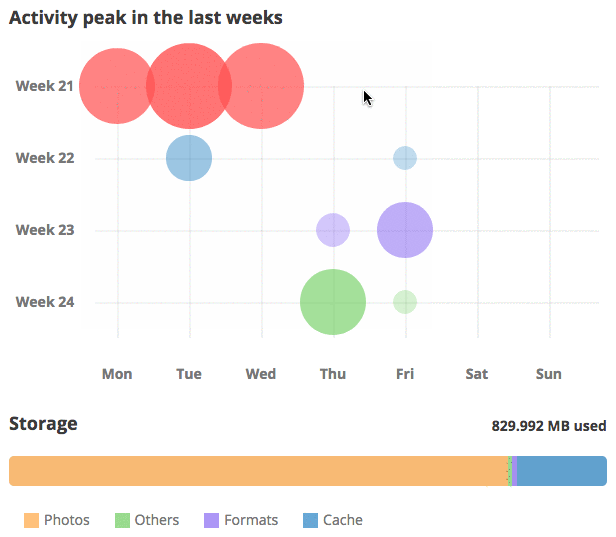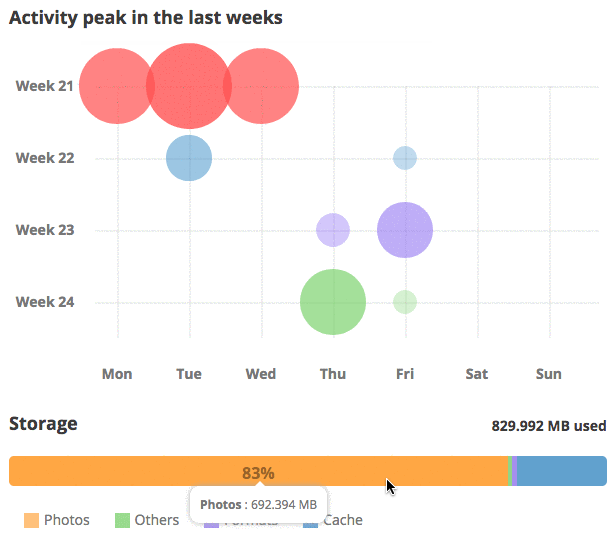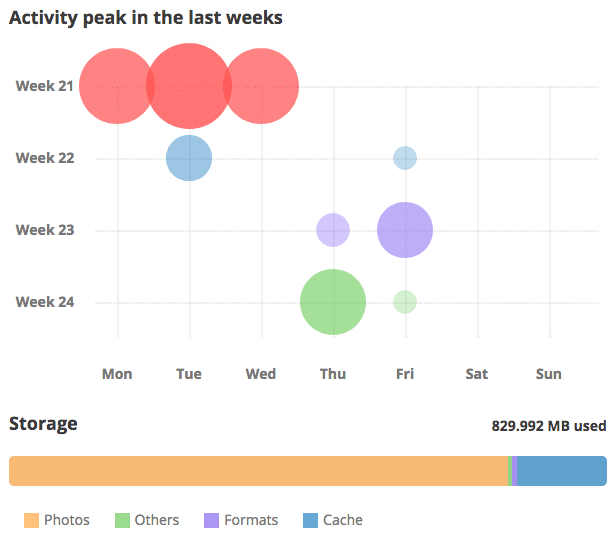
Managing your Piwigo: what’s new in Piwigo 11
Here comes the last episode of our series of articles dedicated to Piwigo 11. It’s time to review the new features dedicated to the management and administration of your photo library itself.
Continue Reading Managing your Piwigo: what’s new in Piwigo 11
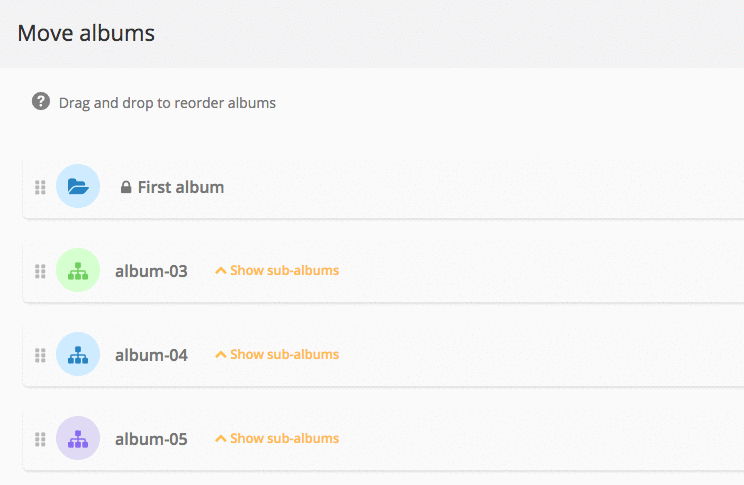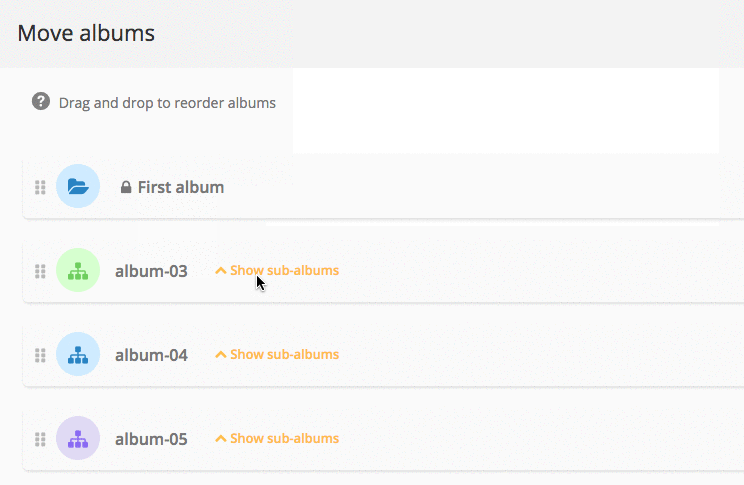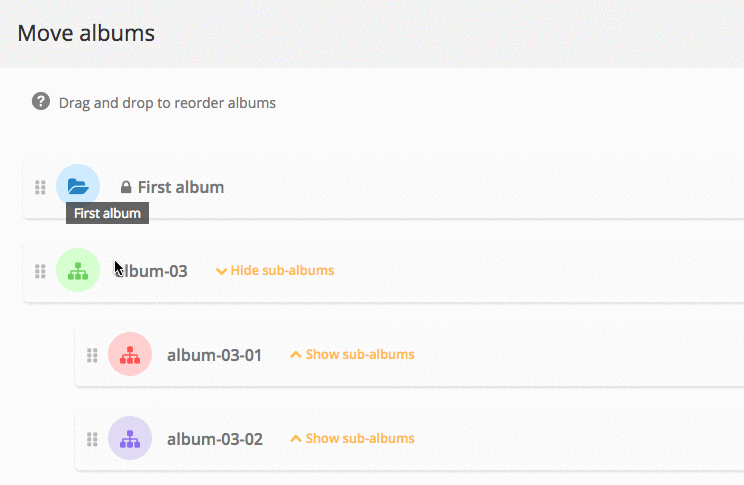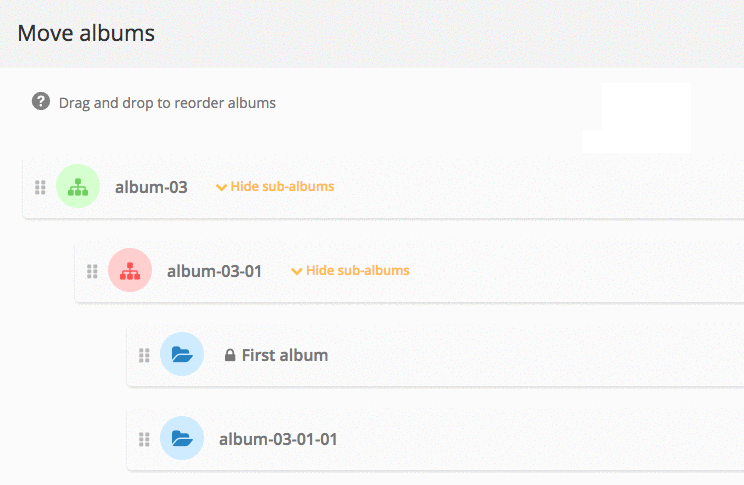
Album management: what’s new in Piwigo 11
Piwigo v11 comes with many new features for managing and organizing your albums: we explain everything in this blog post.
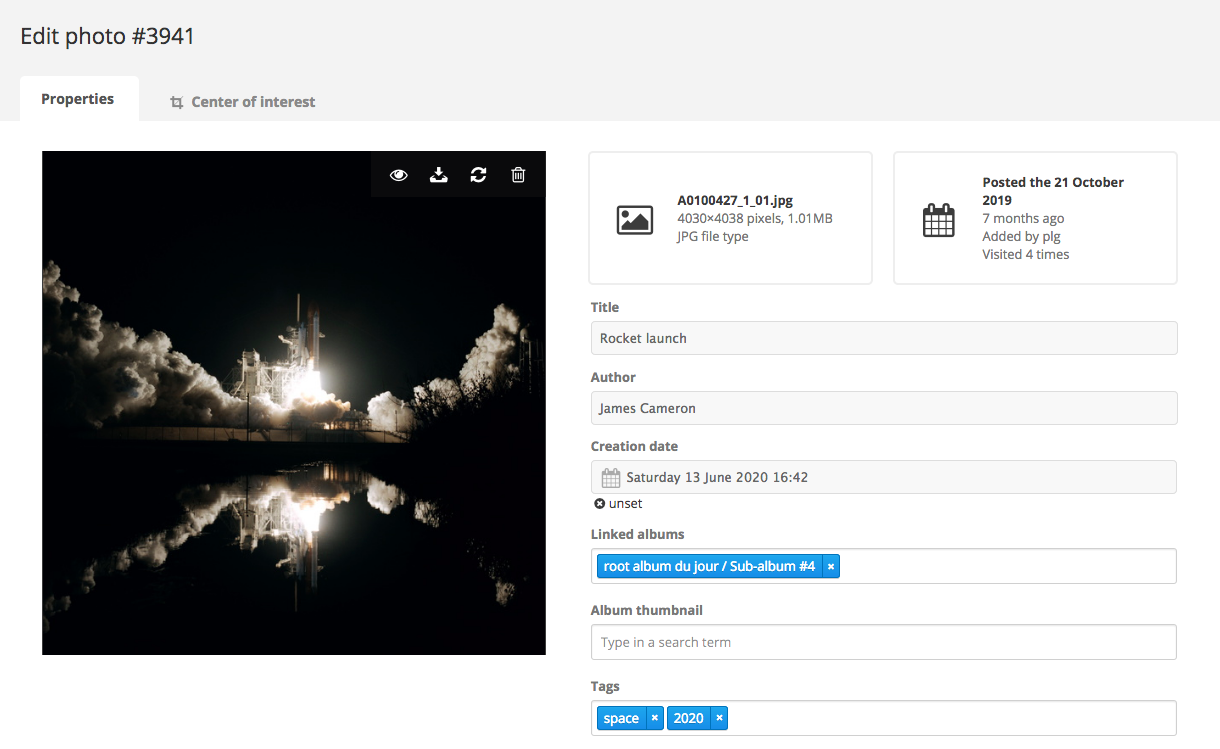
Photo Management : what’s new in Piwigo 11
Discover in this blog post the new features of Piwigo 11 photo management: photo editor, tag manager, batch manager…
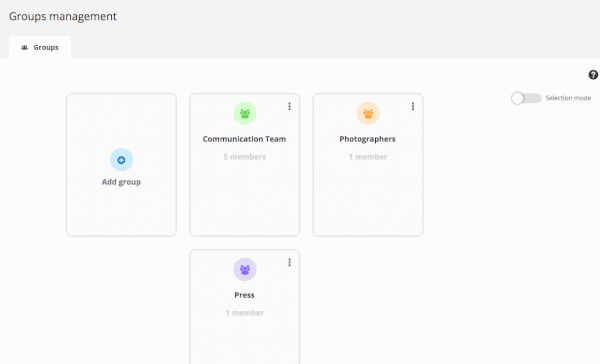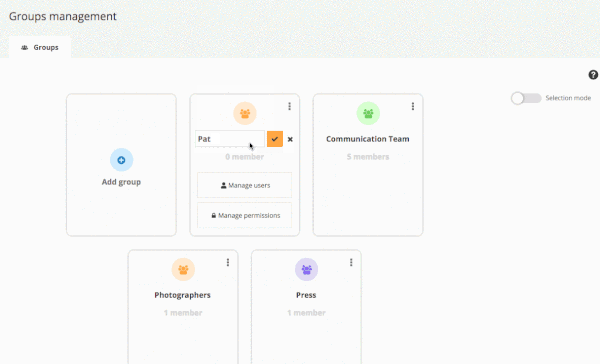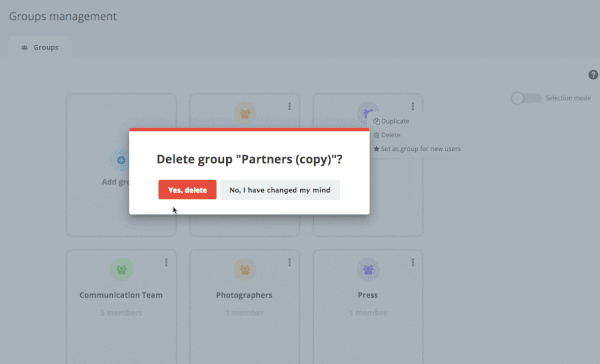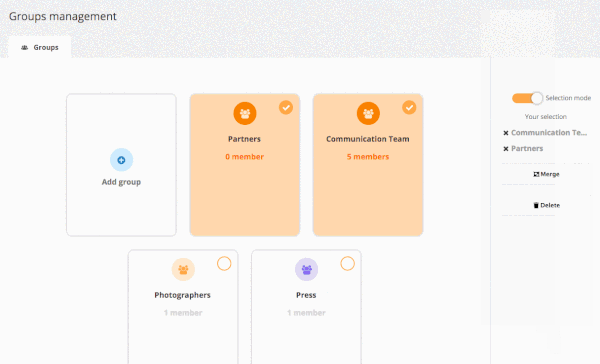
User Management : what’s new in Piwigo 11
Piwigo 11 is deployed for most of our customers! Today, we focus on the new features brought on user management.

Fire at OVH datacenters: no impact on your Piwigo account
A fire broke out yesterday at the Strasbourg site of the French hosting company OVH. No Piwigo customer data is known to have been lost.
Continue Reading Fire at OVH datacenters: no impact on your Piwigo account
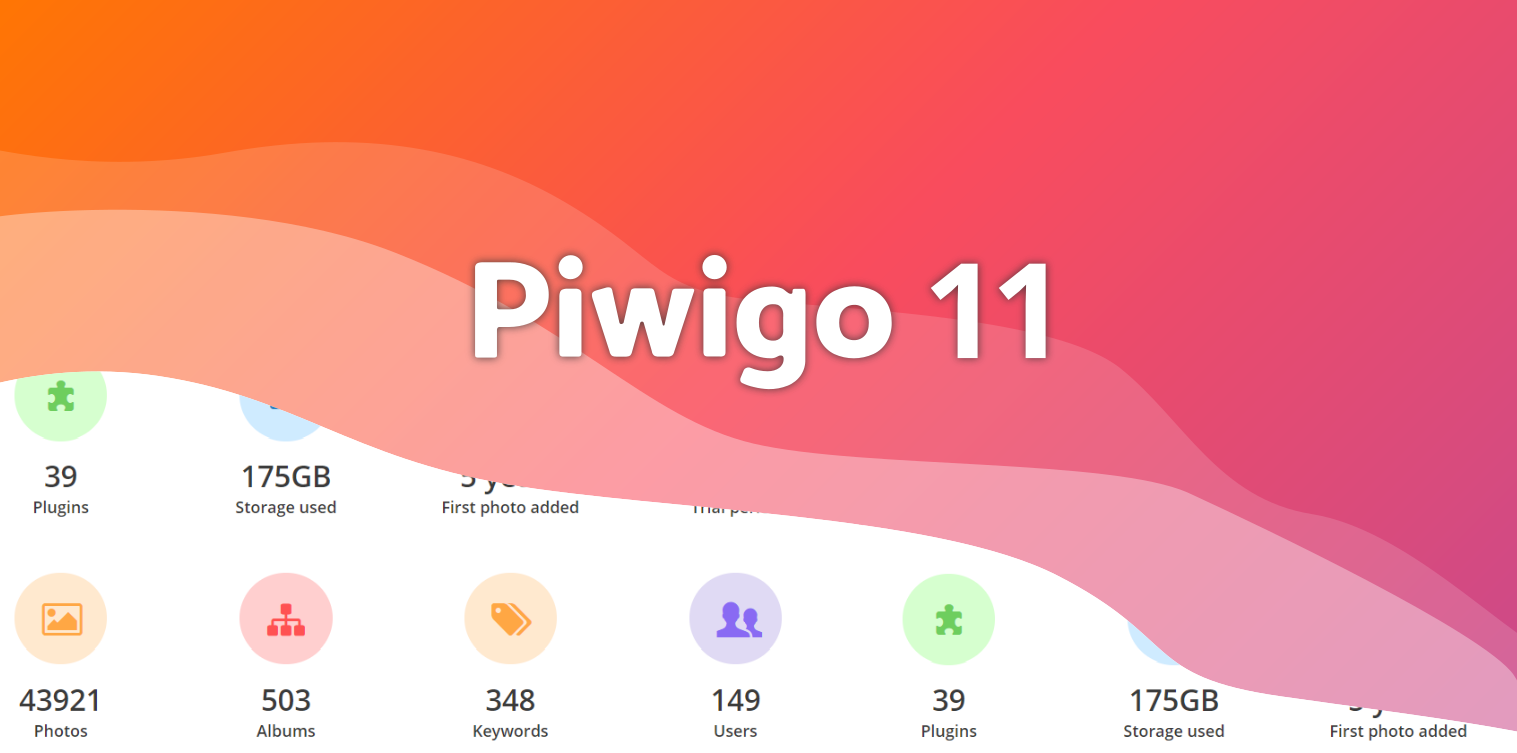
Piwigo v11: get ready for some changes!
A new version of Piwigo will be coming soon. What is this v11? What to expect? We’ll explain everything to you!
Need an image gallery software ?
Try Piwigo free for 30 days !
